
「S&P500」や「オルカン」。 資産形成を志す人なら、この名前を聞かない日はありません。しかし、その数字が「具体的にどのような計算式で算出されているか」を気にかけたことはあるでしょうか?
多くの人は、インデックスを単なる「株価の平均」だと思っています。 ですが、現役エンジニアである私の視点では、あれは単なる平均値ではありません。市場という膨大なデータから、ノイズを除去し、自動的に成長トレンドだけを抽出するように設計された「堅牢なデータ処理システム」に見えます。
なぜ、素人がプロの投資家に勝ててしまうのか。 なぜ、構成銘柄が入れ替わっても暴落しないのか。
この記事では、投資信託のパンフレットには載っていない「インデックス(指数)の内部仕様」を、エンジニアリングの視点から解剖します。 精神論ではなく、数理モデルとしての「勝てる理由」を知りたい方への記事です。
インデックス投資の正体:それは「市場データ」を正規化した計算結果
多くの投資家は、S&P500や日経平均株価のチャートを見て「値段が上がった・下がった」と一喜一憂します。しかし、エンジニアやデータアナリストの視点で見ると、あれは単なる「値段」ではありません。
インデックスとは、市場という巨大なシステムの「出力データ」を、人間が分かりやすいように「正規化(決められたルールで数値を整えること)」した計算結果に過ぎないのです。
なぜ、この「計算された数字」を買うだけで、私たちはプロの投資家に勝てるのでしょうか? その秘密を解明するために、実際の市場データを使って「ある検証」を行いました。
なぜ「平均」をとるだけで、プロの投資家に勝ててしまうのか
結論から言います。インデックス投資が強い理由は、「ごく一部の天才的な銘柄(外れ値)を、絶対に逃さない仕組みだから」です。
これを理解するために、まずは学校で習ったはずの「平均値」と「中央値」の違いを、少し極端な例で思い出してみましょう。
「平均値」と「中央値」の決定的な違い
あるクラスの同窓会における「年収」を想像してみてください。
- 中央値(メジアン): 参加者全員を年収順に並べたとき、ちょうど「真ん中」に来る人の年収です。これが「普通の人の感覚」に一番近くなります。
- 平均値(ミーン): 全員の年収を足して、人数で割った数値です。
ここで、もし同窓会に大谷翔平さん(超高年収)が一人だけ遅れて参加したらどうなるでしょうか? 「真ん中の人(中央値)」の年収はほとんど変わりませんが、大谷さんが加わることで「平均値」だけが爆発的に跳ね上がりますよね。
実は、株式市場でもこれと同じことが起きています。
【検証結果】市場データが示す「残酷な現実」
論より証拠です。米国の主要企業100社(S&P100)の過去5年間のデータを用いて、「それぞれの銘柄が何倍になったか」をヒストグラム(度数分布図)にしてみました。
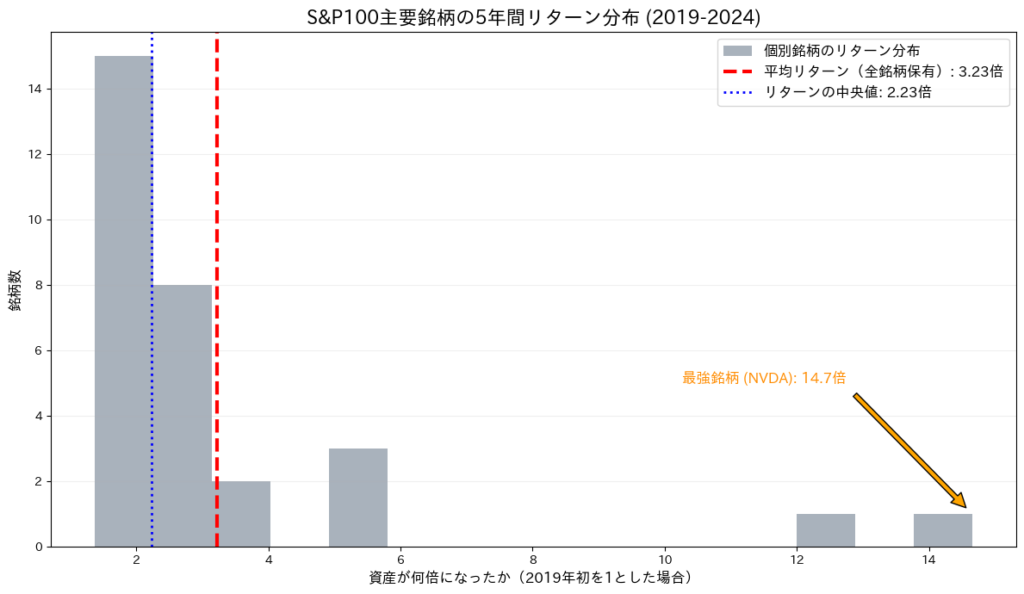
このグラフから、衝撃的な事実が読み取れます。
- 大半は「普通」の塊: グラフの左側に、多くの企業が固まっています。これらの中央値(青い点線)は、そこそこの成績です。
- 右側に「離れ小島」がある: 塊から大きく離れた右側に、ポツンポツンとデータが存在しているのが見えますか? これがNVIDIAやAppleのような、桁外れのリターンを叩き出したごく一部の「怪物銘柄」です。
- 平均(赤線)は右に引っ張られる: この少数の怪物たちに引き上げられ、平均値(=インデックスのリターン)は、中央値よりも高い位置に設定されます。
このデータが示唆するのは、「自分で適当に(ランダムに)銘柄を選ぶと、高い確率で『中央値(平均以下)』の結果になってしまう」というリスクです。 平均点以上の成績を出せる銘柄は、実は全体の3割程度しかありません。「平均点を取る」というのは、直感に反して難しいことなのです。
インデックスは「価格」ではなく「システム」である
一方で、インデックス(S&P500など)を買うということは、「市場全体を丸ごと買う」ことを意味します。つまり、そのパッケージの中には必ずこの「怪物銘柄」が含まれています。
- 個別株投資: 砂山の中から、数個しかないダイヤモンド(超成長株)を探し当てるゲーム。外せば、その他大勢の「平均以下」の成績になります。
- インデックス投資: 砂山ごと全部買うゲーム。余計な砂も買いますが、ダイヤモンドも100%確実に入手できます。
S&P500などの指数は、基準日(昔のある日)の時価総額を「10」や「100」といった扱いやすい数字(定数)に置き換えてスタートしています。これを「正規化(Normalization)」と呼びます。 個々の企業のドラマやニュースといった「ノイズ」を削ぎ落とし、市場全体のエネルギー総量だけを抽出する。それがインデックスというシステムの正体なのです。
【読者への問いかけ】 あなたのポートフォリオ(資産の組み合わせ)を見直してみてください。「次の大化け株」を自分の力で探し出そうとしていませんか? それとも、「大化け株が含まれているパッケージ全体」を保有する安心感を選びますか?
「除数(Divisor)」という魔法:なぜ銘柄が入れ替わっても指数は急落しないのか
インデックス投資をしていると、定期的に「銘柄の入れ替え」が行われるというニュースを耳にします。 例えば、業績が悪化した企業が外され、新興企業が採用されるときです。
ここで一つ、エンジニアらしい疑問を持ってください。 「構成銘柄が変わって時価総額の合計がいきなり変動したら、指数のグラフもガクンと段差ができてしまうのではないか?」と。
しかし、実際のチャートは滑らかに繋がっています。これを実現しているのが、「除数(Divisor)」による補正ロジックです。
時価総額加重平均の「裏側の計算式」
私たちが普段見ているS&P500などの指数は、単純な足し算ではありません。基本的には以下のモデルで計算されています。
- Pi : 各銘柄の株価
- Qi : 浮動株調整済みの株式数
- Divisor : 連続性を保つための除数
この「除数」こそが、インデックスを単なる「合計金額」から「信頼できる指標」へと変える重要なパラメータです。
【検証】Pythonによる除数調整シミュレーション
言葉での説明だけでは「本当か?」と思われるかもしれません。そこで、Pythonを使って「時価総額が急変動する銘柄入れ替え」をシミュレートし、指数がどう挙動するかを検証しました。
▼ シミュレーション条件
- 初期状態: 3銘柄(A, B, C)で構成される指数。
- イベント: 銘柄C(時価総額小)を除外し、銘柄D(時価総額大)を新規採用する。
- 時価総額の変化: 銘柄入れ替えにより、市場全体の時価総額は大きく増加する。
検証結果の考察: グラフの青い棒(時価総額)は右側で大きく伸びていますが、赤い線(指数値)は「100」のまま微動だにしていません。 これは、プログラム内部で「旧除数 5000」から「新除数 6000」へと、システムが除数を自動アップデートしたためです。
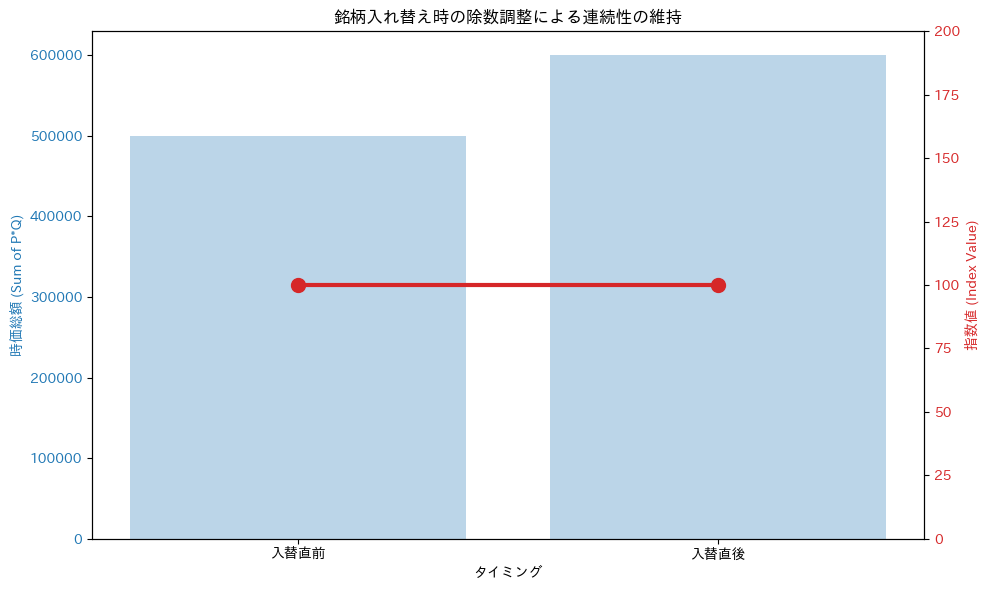
入れ替え前指数: 100.00
入れ替え後指数 (除数調整後): 100.00
旧除数: 5000.00 -> 新除数: 6000.00
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# 日本語表示の設定(環境に合わせて適宜調整)
try:
import japanize_matplotlib
except ImportError:
import subprocess
subprocess.check_call(["pip", "install", "japanize-matplotlib"])
import japanize_matplotlib
def simulate_index():
# 1. 初期設定:3銘柄の時価総額加重平均
# 銘柄A, B, C の株価と発行済株式数
prices = np.array([100.0, 200.0, 150.0])
shares = np.array([1000, 500, 2000])
# 時価総額の合計
market_cap_initial = np.sum(prices * shares)
# 初期除数 (Divisor) を設定(初期指数を100とする場合)
divisor = market_cap_initial / 100
# 2. 銘柄入れ替えのシミュレーション
# 銘柄Cが除外され、新銘柄Dが採用される
# 銘柄Dのスペック
price_d = 500.0
share_d = 800
# 入れ替え直前の時価総額(価格変動なしと仮定)
market_cap_pre = np.sum(prices * shares)
index_pre = market_cap_pre / divisor
# 新しい時価総額(Cを抜き、Dを入れる)
market_cap_post = (prices[0]*shares[0]) + (prices[1]*shares[1]) + (price_d * share_d)
# 3. 除数の再計算 (Divisor Adjustment)
# 指数値(100)を維持するために、新しい除数を求める
# index_pre = market_cap_post / new_divisor => new_divisor = market_cap_post / index_pre
new_divisor = market_cap_post / index_pre
# 検証:新しい除数で計算した指数
index_post = market_cap_post / new_divisor
print(f"入れ替え前指数: {index_pre:.2f}")
print(f"入れ替え後指数 (除数調整後): {index_post:.2f}")
print(f"旧除数: {divisor:.2f} -> 新除数: {new_divisor:.2f}")
# 可視化用の簡易プロット
labels = ['入替直前', '入替直後']
market_caps = [market_cap_pre, market_cap_post]
indices = [index_pre, index_post]
fig, ax1 = plt.subplots(figsize=(10, 6))
color = 'tab:blue'
ax1.set_xlabel('タイミング')
ax1.set_ylabel('時価総額 (Sum of P*Q)', color=color)
ax1.bar(labels, market_caps, color=color, alpha=0.3, label='時価総額')
ax1.tick_params(axis='y', labelcolor=color)
ax2 = ax1.twinx()
color = 'tab:red'
ax2.set_ylabel('指数値 (Index Value)', color=color)
ax2.plot(labels, indices, color=color, marker='o', linewidth=3, markersize=10, label='指数値')
ax2.set_ylim(0, 200)
ax2.tick_params(axis='y', labelcolor=color)
plt.title('銘柄入れ替え時の除数調整による連続性の維持')
fig.tight_layout()
plt.savefig('index_simulation.png')
simulate_index()このシミュレーションから、インデックスが「市場の金額そのもの」ではなく、「連続性を担保された設計物」であることが数学的に確認できました。
【読者への問いかけ】 投資信託の構成銘柄が変わるニュースを見たとき、その裏側で「計算式のメンテナンス」が行われていることを想像したことはありますか? 私たちが投資しているのは、個別の企業ではなく、この「新陳代謝システム」そのものなのです。
自己修復アルゴリズム:時価総額加重平均が「勝手に」勝ち組を選ぶ仕組み
投資において最も難しく、かつパフォーマンスを左右する決断は何でしょうか? それは「いつ買い、いつ売るか」というリバランスの判断です。
多くの個人投資家は、ここで感情に負けます。「もう少し待てば戻るかもしれない(損失回避バイアス)」と考えたり、「高すぎて買えない」と躊躇したりします。 しかし、インデックス(時価総額加重平均型)は、この人間的な迷いを一切排除した冷徹なアルゴリズムによって運用されています。
「順張り」を自動化するポジティブフィードバック
S&P500やオール・カントリー(オルカン)が採用している「時価総額加重平均」の本質は、エンジニアリングで言うところの「ポジティブフィードバック・ループ」です。
補足:「ポジティブフィードバック」とは? 専門的な響きですが、簡単に言えば「雪だるま式」のことです。 雪だるまは、転がれば転がるほど大きくなり、大きくなればなるほど、さらに多くの雪を巻き込めるようになりますよね。
- 入力(雪がつく)→ 出力(大きくなる)→ さらなる入力(もっと雪がつく)…
このように「結果が原因を強化し、どんどん加速していく循環」のことを指します。インデックス投資においては、「株価が上がった(成功した)企業ほど、さらにポートフォリオ内での存在感が増していく」という仕組みを意味します。
仕組みは極めてシンプルです。
- 株価が上がる(市場評価が高まる): 時価総額が増えるため、ポートフォリオ内の構成比率(Weight)が自動的に増加します。つまり「買い増し」が行われます。
- 株価が下がる(市場評価が下がる): 時価総額が減るため、構成比率が自動的に減少します。つまり「売り(損切り)」が行われます。
このロジックが24時間365日稼働し続けることで、インデックスは常に「その瞬間の勝ち組」を最大保有し、「負け組」を縮小させる状態を維持します。
「新陳代謝(メタボリズム)」という機能
このアルゴリズムの優秀さは、歴史を見れば一目瞭然です。 もしS&P500が「固定された銘柄」のリストだったら、とっくの昔に崩壊していたでしょう。かつて世界を支配していたGE(ゼネラル・エレクトリック)やエクソンモービルも、その輝きが失われれば、容赦なく構成比率を下げられ、やがてはトップ10から姿を消します。
代わりに、当時は海のものとも山のものともつかなかったGoogleやAmazon、そしてNVIDIAといった新興勢力が、実績(時価総額)を上げるにつれて自動的にポートフォリオの主役に躍り出ました。 主役は時代ごとにガラリと変わりますが、インデックスそのものは右肩上がりを続けています。それは、「中身を入れ替える(新陳代謝する)」ことこそが、このシステムの仕様だからです。
感情を持たない「ガベージコレクション」
プログラミングには、不要になったメモリ領域を自動的に解放する「ガベージコレクション」という機能がありますが、インデックスも似た働きをします。
- 個別株投資家の場合: 「あの時あんなに輝いていた企業だから…」と、没落する企業に愛着や未練を持ってしまい、ポートフォリオに残存させてしまいます(塩漬け)。
- インデックスの場合: 時価総額という「数字」が下がれば、問答無用でウェイトを下げ、最終的には指数から除外(パージ)します。そこには過去の栄光や感情は一切介在しません。

このイラストは、インデックス内部の処理を可視化したものです。まるで自動化された工場のように、システムが淡々と選別作業を行っています。 時価総額が大きくなり、輝きを増した「成長企業(ピカピカの箱)」はメインのラインへ丁寧に積み上げられ、逆に競争力を失って錆びついてしまった「衰退企業(錆びた箱)」は、自動的にリサイクル(除外)のラインへと弾かれていきます。
私たちがインデックス投資で得ている利益の源泉は、企業の成長だけではありません。この「人間の感情を排除した、徹底的な損小利大の自動売買プログラム」を利用していることへの対価でもあるのです。
【読者への問いかけ】 あなた自身の判断力と、この冷徹な「自動修復アルゴリズム」。これから20年続く資産形成のパートナーとして、どちらの方が信頼性が高いと感じますか?
フィルタリング強度の違い:オルカンからFANG+までを「サンプリング密度」で解剖する
市場には、毎日数えきれないほどのデータ(株価、出来高、ニュース)が流れています。これを巨大な「データの海」だと想像してください。 インデックス投資とは、この海から魚(リターン)を捕獲する行為です。
では、同じインデックスでも、「S&P500」と「NASDAQ100」や「FANG+」は何が違うのでしょうか? それは、以下のイラストのように、「魚を捕るための『網』の設計(フィルタリングの強度)」が根本的に異なります。
この3つのイラストは、左から順に「広域(S&P500など)」「特化(NASDAQ100など)」「集中(FANG+など)」のアプローチを表しています。それぞれの特徴を、エンジニアリングの視点で見ていきましょう。

広域センサー:市場全体のスループットを監視(オルカン、S&P500)
- イラストの対応: 左側の「巨大な定置網」
- 設計思想: 「網羅性」と「堅牢性」
「全世界株式(オール・カントリー)」や「S&P500」は、市場全体の動き(スループット)をできる限り漏らさず捉えようとする設計です。 特定の業種や国に偏らず、時価総額の大きなものを中心に広くサンプリング(抽出)します。
- メリット: どこかで予期せぬ「大物(次のGAFAM)」が現れた時、必ず網にかかります。機会損失を最小限に抑えられる、最も堅牢なシステムです。
- デメリット: イラストの網の中に雑多な魚がいるように、成長性の低い企業や、不祥事を起こした企業のデータ(ノイズ)も一緒に拾ってしまうため、瞬間的な爆発力は控えめになります。
特定モジュール特化:高出力エンジンにフォーカス(NASDAQ100, SOX指数)
- イラストの対応: 中央の「特定の魚を狙う網」
- 設計思想: 「効率性」と「モメンタム(勢い)」
「NASDAQ100」は、金融セクターを除外し、ハイテクやバイオといった成長産業(モジュール)に特化してサンプリングします。「SOX指数(半導体)」はさらに対象を絞り込みます。 これは、市場全体の平均点ではなく、経済を牽引する「高出力エンジン」(イラストでは光る速い魚)の性能だけを測定しようとする設計です。
- メリット: 成長セクターの勢いがそのままリターンに直結するため、ハマれば市場平均を大きく上回ります。
- デメリット: 狙ったセクターが不調に陥った場合、逃げ場がなくなり、ダメージが直撃します(ドットコムバブル崩壊時のNASDAQなど)。
オーバーサンプリング:極端な偏りによる高負荷テスト(FANG+, MAG7)
- イラストの対応: 右側の「一点狙いの銛(もり)」
- 設計思想: 「現在最強への集中」
「FANG+」や「Magnificent 7(MAG7)」は、インデックスと名は付いていますが、その実態は「現在最強の数社(イラストの巨大な金のクジラ)への集中投資パッケージ」です。 統計学的に言えば、特定のデータ(現在の勝者)を過剰に抽出する「オーバーサンプリング」の状態です。しかも、FANG+などは時価総額加重ではなく「均等加重」を採用することが多く、これは「さらにリスクを取ってリターンを追求する」というアグレッシブな仕様書に基づいています。
- メリット: 現在のトレンドが続く限り、他の追随を許さない圧倒的なリターンを叩き出します。
- デメリット: 分散効果はほぼありません。構成銘柄の数社が同時にコケた場合、システム全体のパフォーマンスが崩壊するリスクを常に抱えています。これは「高負荷試験(ストレステスト)」のような投資です。
まとめ:あなたはどの「仕様書」を選ぶのか
これらは、どれが優れているという話ではありません。「システムの目的(仕様)」が違うだけです。
| 指数(システム) | フィルタリング強度 | 目的(仕様) | エンジニア的解釈 |
| オルカン/S&P500 | 弱(広域) | 市場全体の平均的な成長を享受する | 堅牢な基幹システム。ダウンタイム(暴落からの回復不能)を避ける設計。 |
| NASDAQ100 | 中(特化) | テック産業の成長速度を享受する | 特定機能に特化した高性能モジュール。速いが熱暴走(バブル)のリスクも。 |
| FANG+/MAG7 | 強(集中) | 現在の覇者の最大瞬間風速を享受する | 限界性能を試すオーバークロック設定。リターンは凄まじいが、常に監視が必要。 |
インデックス投資で失敗する最大の原因は、自分が採用したシステムの「仕様書」を読まずに、「S&P500よりFANG+の方が儲かるらしい」といった表面的な数字だけで乗り換えてしまうことです。
【読者への問いかけ】 今のあなたのポートフォリオは、市場全体の「スループット(平均点)」を見たいのでしょうか? それとも、特定エンジンの「最大瞬間風速」を期待しているのでしょうか? 目的と手段(採用する指数)は一致していますか?
まとめ:インデックス投資とは、市場という「計算機」への信頼である
ここまで、インデックス(指数)というものを、エンジニアリングの視点から解剖してきました。
私たちが普段ニュースで目にする「S&P500の最高値更新」という見出し。その裏側では、これほどまでに精巧なアルゴリズムが動いていたのです。
- 正規化: バラバラな企業の価値を、統一された基準で測定可能なデータに変換する。
- 除数調整: 構成銘柄が入れ替わっても、数字が途切れないように連続性を数学的に担保する。
- 自己修復: 人間の感情を介さず、市場の評価に基づいて自動的に新陳代謝を繰り返す。
- フィルタリング: 目的に応じて、市場全体を網羅したり、特定の成長エンジンだけを抽出したりする。
投資を「ギャンブル」から「データ処理」へアップデートせよ
多くの人が投資を怖がるのは、それが「丁半博打」のように見えているからです。明日の株価が上がるか下がるか、誰にも分からないことに大切なお金を賭けるのは恐怖でしかありません。
しかし、インデックスの仕組みを理解した今、景色は変わったはずです。 インデックス投資とは、未来を予言することではありません。「資本主義市場という巨大な計算システムが、長期的には成長トレンドを描く(=スループットが向上する)」という仕様を信頼し、その出力結果に乗っかる行為です。
もちろん、システムにもバグや障害(=大暴落や長期停滞)はつきものです。しかし、個別の銘柄選びという不安定な手作業に頼るよりも、自己修復機能を持った堅牢なシステムに資産を委ねるほうが、合理的で誠実な選択ではないでしょうか。
最後に:システムを信じて「計算」を止めないこと
明日も市場は開き、株価はランダムに動き、あなたの感情を揺さぶるでしょう。 暴落が来て恐怖で売りたくなったとき、あるいはバブルが来て興奮で買い増したくなったとき、ぜひこの記事で見た「工場のイラスト」や「数理モデル」を思い出してください。
あなたの感情とは無関係に、インデックスというシステムは淡々と計算を続け、不良債権を処理し、新しい成長を取り込み続けています。 私たち投資家にできる最大の仕事は、余計な操作をしてシステムを邪魔せず、この「富の再生産プロセス」が回り続けるのを忍耐強く見守ることだけなのです。
【最後の問いかけ】 インデックスの「仕様書」を読み解いた今、あなたの目には、日々の株価変動がどのように映るようになりましたか? それは恐怖の対象でしょうか、それともシステムが正常に稼働している証拠でしょうか?


コメント