
投資信託の裏側で動く「コピーの仕組み」の正体
多くの投資家にとって、インデックスファンドは「お金を入れたら、自動的に指数の動きに合わせて増減する箱」に見えているかもしれません。しかし、その箱の中では、運用会社のプロたちが「理想(指数)」と「現実(市場)」のギャップを埋めるために、日々汗をかいています。
私たちが普段、完璧なコピー商品を作ろうとするとき、材料の調達コストや手間を考えるのと同じように、運用会社も「いかに効率よく、指数の動きを再現するか」に知恵を絞っています。
今回は、パンフレットの表面的な数字ではなく、その裏側にある「運用の仕組み」にフォーカスを当てます。「全部の銘柄を買う」というシンプルな方法と、「主要な銘柄だけを選んで買う」という工夫された方法の違いを知ることで、あなたの持っているファンドがどう動いているのか、クリアに見えるようになります。
パンフレットの裏側にある「設計図」を読み解く
インデックス投資の目的は、ベンチマーク(S&P500やMSCI ACWIなど)の成績と同じ動きをすることです。しかし、指数という「計算上の数字」には、手数料も税金もありません。一方、運用担当者は、コストのかかる現実世界でその数値を追いかけなければなりません。
ここで、運用会社は2つの「再現方法」を使い分けます。
- 完全法(完全複写法): 指数に含まれる全銘柄を、そのまま丸ごと買う方法
- サンプリング法: 動きの似ている主要な銘柄だけを選んで買う方法
この2つは、どちらが良い・悪いではなく、「正確さ」と「コスト」のバランスをどう取るかという、料理のレシピのような違いです。
あなたが普段見ている基準価額は、理想の指数とどれくらい「シンクロ」していると思いますか?
全銘柄を愚直に揃える「完全法」の美学と限界
まず紹介するのは、最もシンプルで、ある意味では最も美しい方法である「完全法(完全複写法)」です。
これは、指数に含まれるすべての銘柄を、その構成比率通りに買い揃える手法です。S&P500であれば500銘柄すべてを、TOPIXであれば2,000銘柄以上すべてを保有します。
なぜS&P500ファンドの多くはこの手法を選べるのか
S&P500に連動するファンドの多くが、この「全部買い」を採用しています。理由はシンプルで、「その方が手っ取り早いから」です。
- いつでも買える: S&P500に入っているのはアメリカを代表する大企業ばかり。売り切れや品薄の心配がありません。
- 数がちょうどいい: 500個程度であれば、すべての銘柄を管理するのはそれほど難しくありません。
これは、スーパーで「買い物リスト」にある500品目を上から順にカゴに入れていくようなものです。品物が揃っていれば、リストと中身は完璧に一致します。
銘柄数が増えるほど「手間」と「コスト」が膨らむジレンマ
しかし、この方法は万能ではありません。例えば「オール・カントリー(全世界株式)」のような、約3,000銘柄(小型株を含めるとそれ以上)を対象とする指数の場合、全部を買おうとすると無理が生じます。
- 買えない銘柄が出てくる: 新興国の小さな会社の株など、「買いたいのに売ってくれる人がいない」状態が起きます。無理に買おうとすると、割高な手数料を取られてしまいます。
- 管理が大変すぎる: 3,000銘柄すべてに対して、毎日1円単位で金額を調整し続けるのは、あまりに非効率です。
完璧を目指しすぎると、かえって損をする
すべての銘柄を完璧に揃えることにこだわりすぎて、そのための売買コスト(手数料)が増えてしまえば、肝心のリターンが減ってしまいます。本末転倒です。
これを防ぐため、多くの全世界株式ファンドや新興国株式ファンドでは、次章で解説する「サンプリング法」という工夫を使います。「100点満点の再現」を諦めることが、結果として「合格点のリターン」を維持することに繋がるのです。
3,000種類のスパイスを0.1グラム単位で調合するカレー作りを、毎日続けられるでしょうか?
賢く間引く「サンプリング法」がコストを抑える仕組み
膨大な量の作業を前にしたとき、私たちはどうするでしょうか? すべてを処理するのではなく、要点だけを押さえて効率よく終わらせようとするはずです。
投資信託におけるその工夫が「サンプリング法」です。
全体像を崩さずに「軽量化」するテクニック
サンプリング法では、指数を構成する銘柄をいくつかの「グループ」に分けます。
- 業種: IT、医療、金融など
- 国・地域: アメリカ、日本、インドなど
- 会社の規模: 大企業、中堅企業
そして、各グループの中から「代表選手」となる銘柄だけを選んで買います。例えば、「新興国の素材メーカー」というグループがあれば、売買のしにくい小さな会社50社をすべて買うのではなく、その動きを代表する大きな会社3社だけを買う、といった具合です。
細かい画質を落としても、写真は綺麗に見える
これは画像の圧縮に似ています。スマホで撮った写真を少し圧縮しても、パッと見の印象は変わりませんよね? 人間の目にはわからないレベルで情報を間引いているからです。
投資信託も同じです。全体への影響が小さいマイナーな銘柄を間引いても、ファンド全体の動きは指数とほぼ一致します。
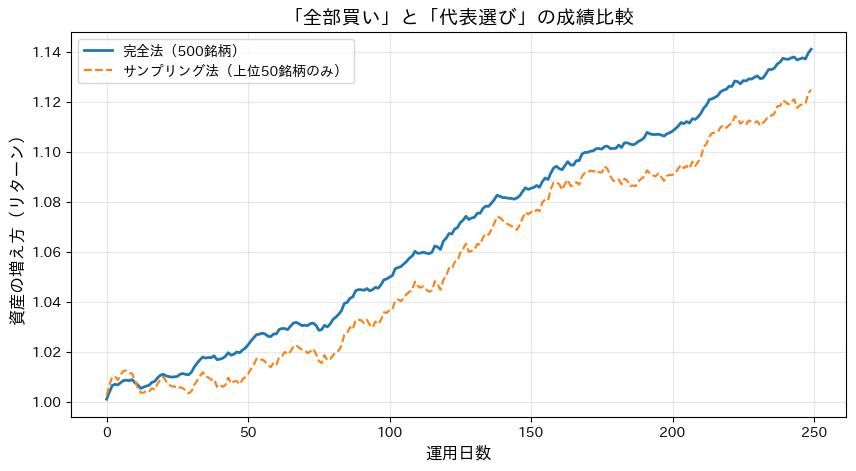
実際に、どの程度の精度が出るのか、シミュレーションを行ってみましょう。500銘柄の指数に対し、そのたった1割にあたる「上位50銘柄」だけを選んだ場合、動きはどうなるでしょうか。
▼ Pythonによる検証:全部買い vs 代表選び
# ※このコードはGoogle Colab等で実行可能です
!pip install japanize-matplotlib
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
# 1. データの生成(500銘柄の仮想指数)
np.random.seed(42)
n_stocks = 500
days = 250
# 時価総額の分布(一部の巨大企業が全体を引っ張る構造を作成)
weights = np.random.pareto(1.5, n_stocks)
weights /= weights.sum()
weights = np.sort(weights)[::-1] # 降順ソート
# 各銘柄の値動きを作成
returns = np.random.normal(0.0005, 0.01, (days, n_stocks))
price_paths = np.cumprod(1 + returns, axis=0)
# 2. 運用手法のシミュレーション
# A. 完全法(500銘柄すべて保有)
index_value = np.dot(price_paths, weights)
# B. サンプリング法(上位50銘柄のみを抽出して保有)
n_sample = 50
sample_weights = weights[:n_sample]
# 選んだ50銘柄だけで100%になるように比率を調整
sample_weights /= sample_weights.sum()
sampled_value = np.dot(price_paths[:, :n_sample], sample_weights)
# 3. グラフで比較
plt.figure(figsize=(10, 5))
plt.plot(index_value, label='完全法(500銘柄)', color='#1f77b4', linewidth=2)
plt.plot(sampled_value, label=f'サンプリング法(上位{n_sample}銘柄のみ)', color='#ff7f0e', linestyle='--')
plt.title('「全部買い」と「代表選び」の成績比較', fontsize=14)
plt.xlabel('運用日数', fontsize=12)
plt.ylabel('資産の増え方(リターン)', fontsize=12)
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
# ズレ(誤差)の確認
error = np.std(sampled_value - index_value)
print(f"サンプリングによるズレの大きさ: {error:.4f}")このコードを実行すると、青線(完全法)とオレンジの点線(サンプリング法)がある程度同じ傾向の動きをするグラフが描かれます。銘柄数を10分の1に減らしても、影響力の大きい主要な銘柄さえ押さえていれば、全体のトレンドは再現できるのです。
「手抜き」ではなく、計算された「効率化」
サンプリング法は決して手抜きではありません。「最小の手間(コスト)で、最高の結果(指数への連動)」を目指すための、計算された戦略なのです。
もちろん、完全に一致することは稀ですが、そのわずかなズレを受け入れることで、私たちは「信託報酬の安さ」という大きなメリットを受け取ることができています。
「ほんの少しのズレ」を受け入れることで、毎年の手数料が安くなるとしたら、あなたはどちらを選びますか?
運用報告書は「デバッグログ」である:ズレ(乖離)を生む4つのノイズ
インデックスファンドを持っていると、必ず直面するのが「指数とのズレ(トラッキングエラー)」です。「ベンチマークは+10%なのに、自分のファンドは+9.8%しかない」といった状況です。
これを「運用が下手だ!」と感情的に捉えるのではなく、システムの「仕様上の誤差」として冷静に分析してみましょう。実は、このズレには明確な理由があり、運用報告書(デバッグログ)を見ればその原因を特定できます。
なぜ「設計通り」に動かないのか?
理論上の指数と、現実の運用には「真空と大気中」くらいの違いがあります。主な抵抗(ノイズ)は以下の4つです。
- 信託報酬などのコスト: 運用会社や信託銀行に支払う手数料です。指数にはこのコストが含まれていませんが、ファンドからは毎日確実に引かれます。これは「物理的な摩擦」のようなもので、必ずマイナス方向のズレを生みます。
- 配当金の税金(パケットロス): 指数(配当込み)の計算では、配当金がそのまま全額再投資される前提になっていることが多いです。しかし、現実には配当金を受け取る際に税金が引かれます。この「税金分の目減り」がズレとなります。
- 売買のタイミングとコスト: 指数構成銘柄の入れ替えがあった際、指数は瞬時に切り替わりますが、ファンドは実際に株式市場で売買しなければなりません。ここにはタイムラグや売買手数料が発生します。
- サンプリングによる誤差: 前章で解説した通り、全銘柄を持たないことによる統計的なズレです。これはプラスにもマイナスにも働きます。
運用報告書の「乖離理由」を読み解く
運用報告書には、必ず「ベンチマークとの差異」という項目があります。ここには、上記のような理由が定量的に書かれています。
- 「信託報酬等のコスト要因で◯%下振れしました」
- 「配当課税の影響で◯%下振れしました」
- 「先物運用の効果で◯%上振れしました」
これを確認することで、そのファンドが「仕方ないコスト」でズレているのか、それとも「運用の不手際(サンプリングの失敗など)」でズレているのかを判別できます。健全なファンドであれば、ズレの大部分はコストと税金で説明がつくはずです。
運用報告書の「乖離の理由」を、単なる言い訳ではなく「システムの特性」として読んだことはありますか?
完璧さよりも「最適化」を:エンジニア視点で選ぶ理想のファンド
最後に、エンジニアが最も気にする「コスト対効果の境界線」について検証します。
「サンプリング法でいいのはわかったけど、やっぱり銘柄数は多いほうがいいんじゃない?」と思うかもしれません。確かに銘柄数が増えれば精度は上がりますが、ある地点を超えると、コスト(手間)に見合うだけの効果が得られなくなります。これを「収穫逓減(しゅうかくていげん)の法則」と呼びます。
どこまで増やせば「十分」なのか?
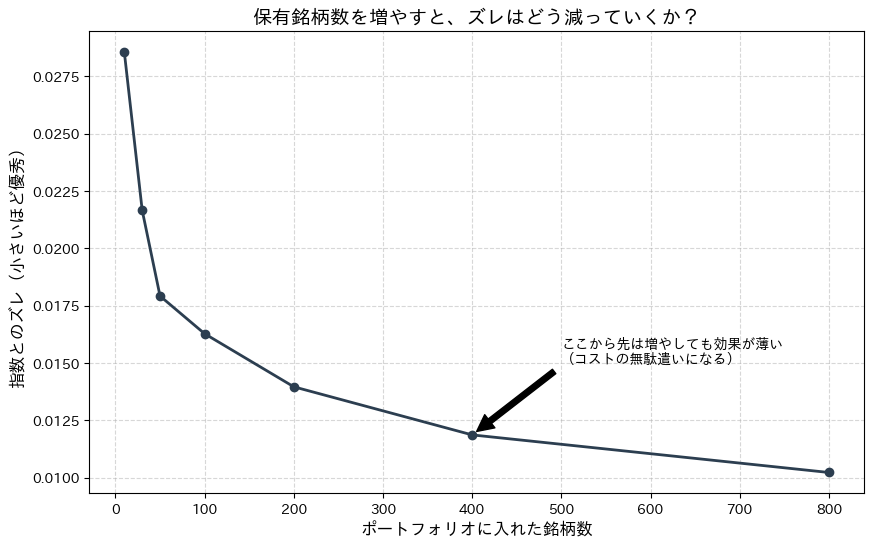
数千銘柄が含まれる指数(全世界株式など)を模倣する場合、何銘柄くらい持てば誤差が許容範囲に収まるのでしょうか? Pythonでシミュレーションしてみましょう。
▼ Pythonによる検証:銘柄数と精度のトレードオフ
# ※このコードはGoogle Colab等で実行可能です
!pip install japanize-matplotlib
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
def verify_sampling_efficiency():
np.random.seed(42)
n_stocks = 2000 # オルカンをイメージした2,000銘柄の指数
days = 250
# 銘柄の重み(時価総額加重:一部の大型株が支配的)
weights = np.random.pareto(1.2, n_stocks)
weights /= weights.sum()
weights = np.sort(weights)[::-1]
# 価格変動データの生成
returns = np.random.normal(0.0005, 0.012, (days, n_stocks))
price_paths = np.cumprod(1 + returns, axis=0)
# ベンチマーク(2,000銘柄すべて保有)
index_value = np.dot(price_paths, weights)
# サンプリング銘柄数を段階的に増やしてズレを計算
sample_sizes = [10, 30, 50, 100, 200, 400, 800]
errors = []
for size in sample_sizes:
# 上位銘柄を抽出してウェイト再配分
s_weights = weights[:size]
s_weights /= s_weights.sum()
sampled_value = np.dot(price_paths[:, :size], s_weights)
# ズレ(標準偏差)の算出
tracking_error = np.std(sampled_value - index_value)
errors.append(tracking_error)
# 結果の可視化
plt.figure(figsize=(10, 6))
plt.plot(sample_sizes, errors, marker='o', color='#2c3e50', linewidth=2)
# グラフの装飾
plt.title('保有銘柄数を増やすと、ズレはどう減っていくか?', fontsize=14)
plt.xlabel('ポートフォリオに入れた銘柄数', fontsize=12)
plt.ylabel('指数とのズレ(小さいほど優秀)', fontsize=12)
plt.grid(True, which='both', linestyle='--', alpha=0.5)
# 解説矢印
plt.annotate('ここから先は増やしても効果が薄い\n(コストの無駄遣いになる)',
xy=(400, errors[5]), xytext=(500, 0.015),
arrowprops=dict(facecolor='black', shrink=0.05))
plt.show()
verify_sampling_efficiency()結果からわかる「最適解」
このグラフを実行すると、銘柄数が少ないうちは急激にズレが減っていきますが、ある地点(例えば200~400銘柄あたり)からカーブが平坦になり、「それ以上銘柄を増やしても、精度はほとんど変わらない」ことがわかります。
運用会社はこの「折れ曲がり地点(エルボーポイント)」を見極めています。 もし3,000銘柄すべてを買おうとすれば、管理コストが跳ね上がり、信託報酬を高くせざるを得ません。しかし、400銘柄程度にサンプリングすれば、「ほぼ同じ精度」を「圧倒的な低コスト」で提供できるのです。
私たちが選ぶべきは、完璧を目指してコストが高いファンドではなく、このように賢く最適化された低コストなファンドです。
「400銘柄でいいと言われても、自分が持っているeMAXIS Slim オルカンなどの銘柄数が400だったら不安…」と思った方もいるかもしれません。安心してください。
実際の人気ファンド(全世界株式)は、約2,500銘柄以上を保有しています。
指数の構成銘柄が約2,500ですので、これはサンプリング法と呼びつつも、実質的には「ほぼ完全複写法」に近い状態です。
● なぜそんなことができる?
数兆円という莫大な資金が集まっているからです。資金規模が巨大であれば、3,000銘柄すべてを買い付けても、相対的な売買コストは極小になります。
● 私たちが受けている恩恵
理論上は400銘柄でも十分な成績が出せますが、人気ファンドは圧倒的な「資金力」というパワープレイで、コストを無視して「精度の極み(全銘柄保有)」を実現してくれています。
つまり、私たちは人気ファンドを選ぶことで、「理論上の合格点」を遥かに超えた「プレミアムな運用」を、格安の手数料で享受できているのです。
あなたの資産形成というプロジェクトにおいて、その誤差は「許容範囲内の仕様」と言えますか?
仕組みを知れば、迷いは消える:合理的投資スタンスのすゝめ
ここまで、投資信託という金融商品の「内部実装」について、エンジニアリングの視点から解剖してきました。
私たちが学んだのは、インデックスファンドが「魔法の打ち出の小槌」ではなく、「コストと精度のトレードオフの中で、極限まで最適化されたシステム」であるという事実です。
「完璧ではない」ことを許容する強さ
完全法であれサンプリング法であれ、運用には必ず「摩擦(コスト)」や「誤差(トラッキングエラー)」が生じます。しかし、それはシステムの欠陥(バグ)ではなく、現実世界で運用を続けるための必要な仕様です。
この仕組みを理解した私たちは、もはや日々のわずかな基準価額のズレや、ネット上の「こちらのファンドの方が0.01%優秀だ」といったノイズに過剰反応する必要はありません。
- 完璧を求めない: 0.1%の精度向上に固執するより、そのコストが適正かを見極める。
- 構造を信じる: 一時的な乖離は「確率的な誤差」であり、長期的には指数に収束することを理解する。
投資は「長いランタイム」を持つプロジェクト
資産形成は、数十年という長い時間をかけて実行されるプロジェクトです。重要なのは、瞬間的な最高速度(リターン)を出すことよりも、システムがダウンすることなく、低コストで淡々と稼働し続けること(継続性)です。
サンプリング法によってコストが抑えられたファンドを選ぶことは、華やかなスペックよりも「保守性」や「運用効率」を重視する、合理的で賢明な選択と言えるでしょう。
仕組みを知ることは、納得感を生みます。そして納得感こそが、暴落時や停滞期においても投資を継続するための、最も頑丈なアンカー(錨)となります。
これからの投資生活、パンフレットの表面的な数字に踊らされることなく、その裏側にある「設計者の意図」と「誠実な実装」に目を向けてみてください。そうすれば、あなたの資産形成はより盤石なものになるはずです。
あなたは今日から、投資信託という「システム」と、どのように付き合っていきますか?


コメント